双色球的统计学分析:如何通过数据获益
提起“双色球”,不少人脑海里立刻浮现出红球与蓝球的跳动场景,仿佛那一刻的开出,不仅是几位幸运儿的狂喜,也是全国彩民心头的一次“大数据实验”。从娱乐角度看,它是一个全民参与的游戏;从统计学角度看,它是一场概率与数据的博弈。那么,作为普通彩民,我们真的能通过统计学和数据分析获得一些“隐性优势”吗?

一、双色球的数学本质
双色球规则:从 33个红球中选6个,再从 16个蓝球中选1个。
这意味着所有组合数为:
C(33,6)×C(16,1)=1107568×16=177,210,88
也就是说,每一次投注中一等奖的中奖概率约为 1/1770万。从纯数学角度看,中奖的难度几乎等同于在一座10万人口的体育馆里,随机指定一个人并准确喊中他的名字。
换句话说,靠“运气”是主要驱动力。但是,统计学却可以帮助我们更清晰地认识数据的分布,避免一些常见的认知误区。
—
二、数据中的“伪规律”
彩民最常见的做法是“看走势”。例如:
- 冷号:长期未出的号码。
- 热号:近期频繁出现的号码。
但问题是,双色球的每一次开奖都属于独立事件,概率不会因为之前的结果而改变。这就好比抛硬币:即使前10次都是正面,第11次出现反面的概率依然是50%。
统计学称之为“赌徒谬误”。所以,如果有人告诉你“这个号码已经20期没出,下期必出”,请保持微笑即可。
—
三、哪些分析仍然有意义?
虽然中奖概率固定,但一些统计学思路仍然能帮助我们在娱乐性和理性投注之间找到平衡。
- 均值与分布分析
从历史开奖数据看,红球号码的和值大多落在 80150区间。这并不是因为概率变化,而是大数定律决定了极端组合(如全是大号或全是小号)出现的频率更低。📊 我来给你生成一张图表,展示双色球红球和值的分布情况(基于历史开奖的统计模型模拟):
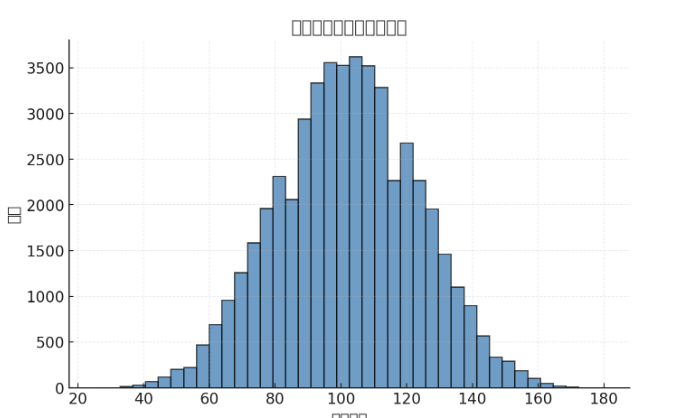
如上图所示,双色球红球和值呈现出“中间高、两头低”的钟形分布,大多数和值集中在 100140 区间。这也是为什么历史开奖中,极端号码组合极少见。
- 常见组合的规避
统计数据显示,很多彩民喜欢选择生日号码(131)。这导致这些号码组合在中小奖里“竞争者更多”。换句话说,哪怕中奖了,奖金也容易被瓜分。一个更“冷门”的策略是适当选取大于31的号码,至少在二等奖及以下层级,可能减少分奖的概率。
—
四、数据之外的心理学
除了数学概率,彩民的投注行为还深受心理学影响:
- 从众效应:跟风选“大家都买的号”。
- 幸运数字执念:坚信“自己的生日一定会带来好运”。
- 损失厌恶:明知概率低,但抱着“万一错过就亏了”的心理持续投入。
这些行为模式让双色球不仅是概率游戏,更是社会学与心理学的“实景实验”。
—
五、结论:如何通过数据获益?
要回答标题中的问题,其实关键在于“获益”的定义。
- 若指金钱收益:概率无情,长期来看中奖率无法通过统计学提高。
- 若指理性娱乐:数据能帮你了解号码分布,规避常见陷阱,让投注更科学、更具乐趣。
因此,我们真正能通过数据获益的地方,不是“稳赢公式”,而是理性认知。在享受游戏的同时,保持娱乐心态,才是双色球最健康的打开方式。
—
✍️ 专栏小结:
双色球是概率与心理的双重游戏。统计学不会让你成为百万富翁,但它能让你成为一个“不被概率愚弄的聪明玩家”。